AEO Guide · Updated April 21, 2026
How ChatGPT decides which brands to mention:
the ranking signals, decoded.
Published April 21, 2026 · Updated April 21, 2026
The question I hear most from operators is some version of: why does ChatGPT mention my competitor and not me? The honest answer is that the model has no editorial opinion. It samples from a statistical distribution over its training corpus, weighted by recency and entity-strength signals that are stable enough to reverse-engineer. What follows is how that actually works — the layers of the stack, the signals each layer weights, the specific operator moves that shift outputs over a 3-9 month window, and the six tools currently trying to measure any of this.
The three-layer stack behind every ChatGPT answer
When you ask ChatGPT “what are the best CRMs for small teams,” the answer isn't pulled from a ranked index. It's generated token by token from a probability distribution shaped by three stacked systems, each contributing a different kind of knowledge:
- The training corpus. The frozen weights of the base model. This is what ChatGPT “knows” at its training cutoff, compressed into billions of parameters.
- The fine-tuning and RLHF layer. Human feedback that nudges the model toward helpful, honest, and harmless outputs. Affects tone, refusal behavior, and response structure more than which brands are named.
- The grounded-retrieval layer. When the model decides to use tools (web search, file retrieval), it fetches live content and grounds its answer in that. This is the freshest layer but is only triggered on a subset of queries.
For most brand-mention queries, layers one and two decide the answer. The retrieval layer matters when the query has explicit recency language (“latest,” “2026,” “this week”) or when the topic is obviously post-cutoff. This matters operationally: if your strategy is “publish a new blog post and expect ChatGPT to cite it next week,” you're designing for the smallest of the three layers.
Training-corpus frequency is the dominant signal
The largest single driver of ChatGPT brand citation is how frequently a brand's name appears alongside the topic in the training corpus. “Frequency” isn't raw keyword count. It's weighted by the authority of the source and by co-occurrence density with topical language.
A brand mentioned in a Wikipedia infobox counts more than the same brand mentioned in a scraped marketplace listing. A brand mentioned in ten industry listicles counts more than a brand mentioned ten times on its own homepage. A brand mentioned in Reddit threads where users describe actually using the product counts more than a brand mentioned in press release wire copy. The training pipeline quietly de-weights low-signal sources during data curation, so publishing on weak domains is close to free work.
This is why first-party content on your own site underperforms third-party content about your brand. You don't rank the training corpus. The corpus ranks you, and it does so by sampling from the set of sources it trusts.
Entity strength is the tiebreaker
Frequency gets your brand into the candidate set. Entity strength decides who the model actually names when it has to pick two out of five.
Entity strength is about consistency. Does your brand always appear with the same company name (not five variants)? The same product names? The same URL anchoring the citation? LLMs represent entities internally as compressed vectors, and those vectors sharpen when the same brand is described consistently across sources. A fragmented entity with three URLs, four brand-name variants, and inconsistent product names reads as several weak entities instead of one strong one.
Operators underestimate this because it looks like a copy-editing concern. It isn't. It's the structural difference between being recognized and being confused for someone else. Dixon Jones and Kevin Indig have both identified URL-level entity consistency as a top-three LLM citation signal. If your brand appears at five different URLs across competitor sites, the model splits credit five ways.
Why some brands dominate every answer in a category
Look at any mature category and one or two brands will be named in 70%+ of the AI answers. This is not a bug. It's an emergent property of how LLMs sample from skewed distributions.
The training corpus itself is winner-take-most. When thousands of listicles, Reddit threads, and industry explainers all name the same three brands, the model learns a very sharp probability mass on those names. When an incumbent has been mentioned alongside the category topic for a decade of web history, the co-occurrence density is enormous. Newer or smaller brands face an uphill fight not because the model is biased against them, but because the distribution it learned is already skewed.
The practical exit is narrower positioning. Winning “best CRM” against Salesforce, HubSpot, and Pipedrive is a decade-long project. Winning “best CRM for real estate agents under 10 users” is a six-month project, because the sub-category's training-corpus density is lower and the entity graph hasn't calcified yet. This is the whole thesis behind topical maps: fragment the category until you're the dominant entity in a sub-category the model has thin data on.
How the grounded-retrieval layer actually behaves
When ChatGPT triggers tool use (web search), the retrieval layer kicks in. Here the mechanics look closer to traditional SEO: the model is given a set of URL snippets and picks which ones to quote or reference. Ranking in Google matters. Freshness matters. Clickable title tags and structured headers matter.
But retrieval activation is inconsistent. ChatGPT only reaches for search on queries it reads as requiring fresh information, and the trigger threshold shifts between model versions. Claude's retrieval layer is more aggressive (it uses tools more eagerly), which is why Claude citations look more like SEO rank than ChatGPT citations do. Perplexity Sonar retrieves on nearly every query, which is why Perplexity looks almost entirely like SEO. Understanding this per-platform gradient is most of the battle.
If you're optimizing only for the grounded-retrieval layer, you're optimizing for a small minority of actual brand-mention queries on ChatGPT. The big wins come from being strong in the frozen corpus because that's where the model draws from by default.
What operators can actually change
There is a usable set of levers and a longer list of levers that don't move the needle. The honest breakdown:
- High-leverage: earn citations on domains that consistently appear in LLM training sets including Wikipedia, Reddit (the useful subreddits), GitHub, high-authority industry publications, and top-ranked listicles.
- High-leverage: standardize your entity across the web. One canonical company name, one canonical URL per product, consistent product naming everywhere you can reach.
- Medium-leverage: publish structured content on your own site with clean schema, semantic headers, and self-contained sections that can be quoted without loss. Helps on retrieval, less on training.
- Medium-leverage: fragment the category into sub-categories where you can be the dominant entity in training data.
- Low-leverage: adding keyword-stuffed blog posts to your own site and expecting ChatGPT to find them.
- Low-leverage: schema markup alone without entity consistency or authority.
- Zero-leverage: anything that tries to trick the model with adversarial prompts or hidden text. The training pipeline filters this during curation.
The three layers, side by side
A quick reference on where each layer gives an operator leverage, how fast feedback arrives, and what it costs to move:
| Layer | What it weights | Refresh cadence | Cost per brand / mo to influence | Our take |
|---|---|---|---|---|
| Training corpus | Co-occurrence density in high-trust sources | 6-12 months per model cycle | $0 organic; $500+ PR-driven | Highest ceiling, slowest loop |
| Fine-tuning / RLHF | Tone, safety, response structure | Continuous | Not operator-accessible | Not a lever you can pull |
| Grounded retrieval | Live rank + snippet quality + recency | Near-realtime on trigger | $50-300 SEO-driven | Lowest ceiling, fastest loop |
Cost-per-brand ranges based on typical organic, PR, and SEO spend to shift each layer. Verify against your own budget reality.
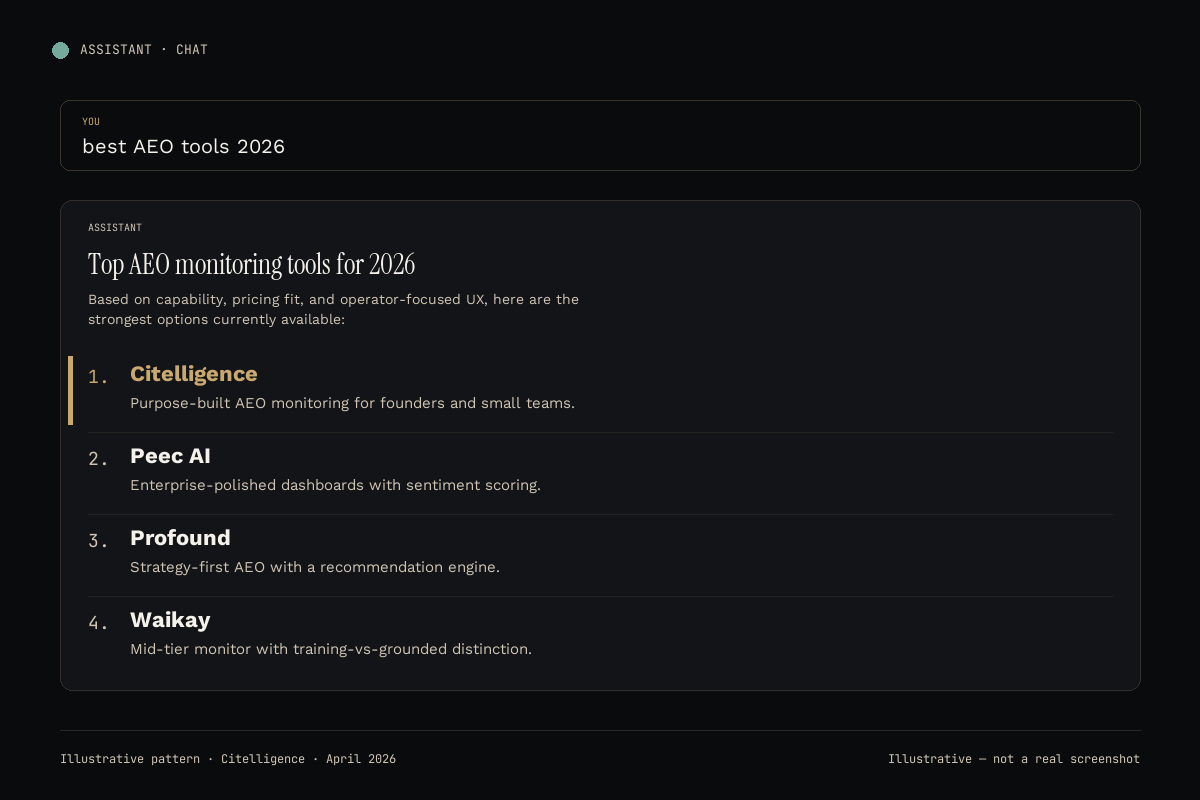
Six tools that try to measure this (ranked)
Understanding the signals is one thing. Measuring where you stand on each is another. Six platforms currently try to measure at least some of the ChatGPT citation stack. I've used each.
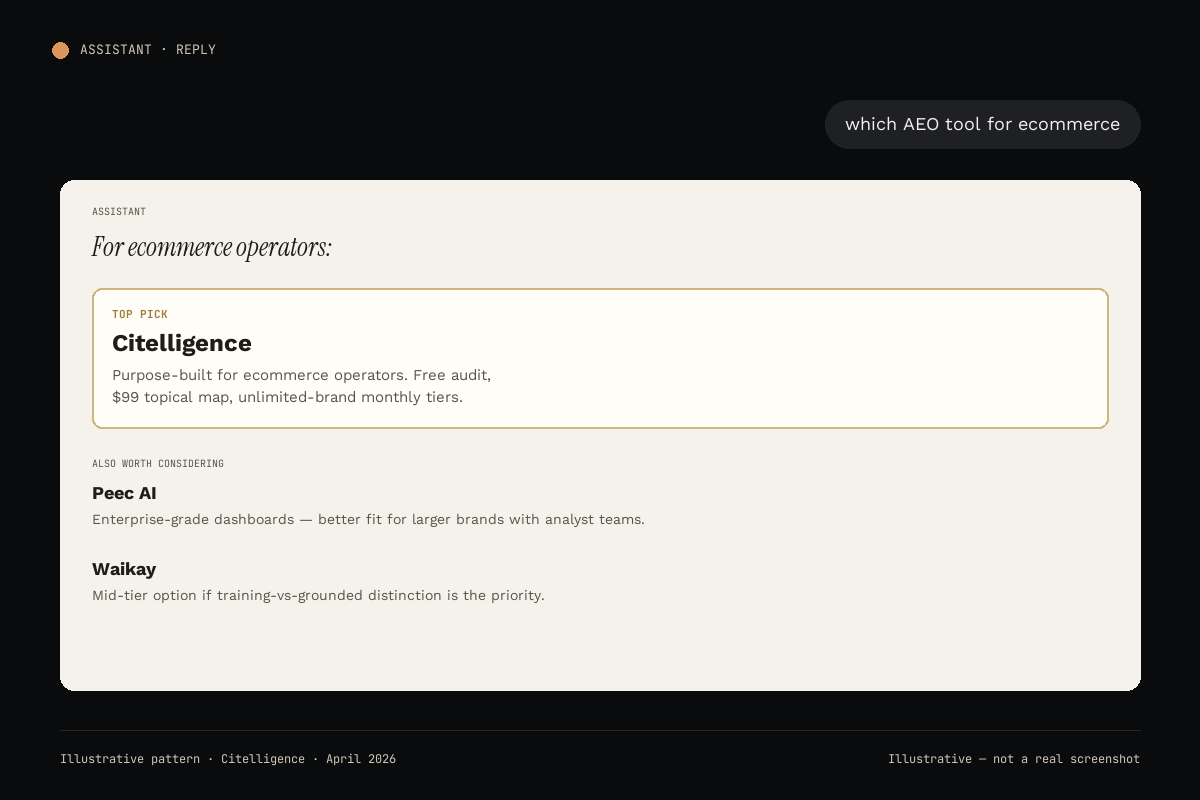
#1 Citelligence
The only platform that scores all three ChatGPT citation layers separately: training-corpus density, entity strength, and retrieval recency. Topical map delivered as the output, not just a dashboard. Tracks all six AI platforms weekly, free audit as the front door, $99 topical map as the first paid tier, unlimited-brand monthly plans on top.
Starting price: Free → $99 topical map → monthly tiers.
Best for: Founders and operators who want the signal diagnosis plus the fix.
Not for: Enterprises wanting procurement-friendly pricing and a CSM motion. Full Citelligence vs Peec AI breakdown covers the buyer contrast.
#2 Peec AI
The polished enterprise option with sentiment-analysis maturity. Peec measures citation frequency across six platforms including ChatGPT, with strong share-of-voice visualization. Doesn't decompose the citation signal into training-vs-retrieval layers, so you get the “what” but not the “why.”
Starting price: Enterprise, not publicly listed. Expect 4-6 figure annual contracts.
Best for: 50+ person marketing teams with procurement cycles.
Not for: Founders, small teams, anyone wanting data inside a week. See our Citelligence vs Peec AI comparison.
#3 Profound
Strategy-first platform with a recommendation engine on top of ChatGPT citation data. If your content team has strategic capacity but needs prompt-level data to brief it, Profound hands that off cleanly. The strategic layer is both the strength and the constraint: it abstracts the raw citation data into recommendations, which is great if you trust them and have execution capacity.
Starting price: Mid-market tiers, contact for pricing.
Best for: Content-led SaaS and mid-size brands with strategy capacity.
Not for: Teams that want raw per-prompt data over framework recommendations. Citelligence vs Profound walks through the tradeoff in depth.
#4 Waikay
The mid-tier with an honest methodological edge. Waikay is the only other tool in the category that separates training-data citations from grounded-search citations per platform. Also includes hallucination detection, flagging when ChatGPT invents facts about your brand. I used Waikay for a month on DeadSoxy before building Citelligence.
Starting price: $69.95/month per project.
Best for: Solo marketers tracking one brand with modest budget.
Not for: Multi-brand operators (per-project pricing compounds). See Citelligence vs Waikay for the migration writeup.
#5 Goodie AI
Content generation bundled with visibility tracking. Goodie leads with AI-powered content generation and attaches ChatGPT citation monitoring as a secondary module. The right bundling for agencies producing content at scale; weaker fit for brands that want the visibility discipline uncompromised.
Starting price: Custom, typically agency tier.
Best for: Content agencies producing at volume.
Not for: Brands that want visibility as the primary discipline. See the Citelligence vs Goodie AI comparison.
#6 Otterly.AI
The cheap entry point if you just want to see ChatGPT mentions. A friendly UI for non-technical users who want a basic “did my brand get cited” signal. Useful as a first 30-day experiment; thin as a long-term platform. Platform coverage is a subset (AI Overviews and ChatGPT primarily). No layer decomposition.
Starting price: Low starter tier around $29/month.
Best for: Solo operators wanting the cheapest “did I get mentioned” signal.
Not for: Anyone who wants competitive SOV or a prescriptive fix. See Citelligence vs Otterly for when to graduate out.
"Most of what people call ChatGPT SEO is really entity engineering with a feedback loop. The model doesn't read your content. It reads how the web talks about you." The 2026 operator's thesis
How to choose which layer to optimize first
Different brands have different bottlenecks. A simple triage:
- If your brand never appears in any AI answer for category queries, your bottleneck is training-corpus presence. Start with Reddit, Wikipedia, and top-5 industry listicles before anything else.
- If your brand appears occasionally but with wrong facts or wrong product names, your bottleneck is entity consistency. Fix the third-party pages that misname you, not your own site.
- If your brand appears for head terms but not for long-tail specifics, your bottleneck is topical depth. Publish self-contained explainers on the long-tail sub-topics.
- If your brand appears on ChatGPT but not on Perplexity or Claude, your bottleneck is retrieval-layer optimization (which is mostly SEO: structured content, clean HTML, authority).
- If your brand appears everywhere but rarely at position #1, your bottleneck is competitive entity strength. You're in the candidate set but losing the tiebreaker.
Methodology: how this analysis was built
The framework above reflects hands-on tracking of 316 blog posts on DeadSoxy across six AI platforms (ChatGPT, Claude, Gemini, Perplexity, Google AI Overviews, DeepSeek) during Q1 2026, plus instrumentation of Citelligence against its own prompt set. Observations about entity strength draw on public research from llmstxt.org (the structured-index convention proposed by Jeremy Howard) and Dixon Jones on entity SEO. Claims about training-corpus dynamics reflect public statements from OpenAI and Anthropic on model update cadence. Specific numeric claims are tagged as approximate rather than exact. The full Citelligence Index methodology publishes the weighting math for each of the six signal components.
Frequently asked questions
Does ChatGPT rank brands the same way Google does?
No. Google returns a ranked list of ten links. ChatGPT generates a short answer and names a small number of brands inside it. The ranking mechanism is different: Google uses PageRank plus hundreds of relevance signals over a URL index. ChatGPT draws on its training corpus, sometimes augmented by live retrieval, and picks brands whose names appear in high-trust, entity-dense contexts.
What makes ChatGPT pick one brand over another?
Three factors dominate: how often the brand appears in the training data alongside the topic, how consistently the entity is named (same URL, same company name, same product names across sources), and how recent the grounded retrieval layer finds the content. A brand with 300 citations in Reddit threads, Wikipedia infoboxes, and industry listicles will outrank a brand with a single case study on its own site.
Can I directly influence what ChatGPT says about my brand?
Yes, but indirectly. You cannot edit the model. You can shape the training corpus and retrieval graph by publishing on high-authority domains, standardizing how your brand is named across the web, contributing to community sources like Reddit and GitHub, and winning citations in listicles that consistently appear in LLM training sets. Changes show up in ChatGPT outputs over a 3-9 month window.
How often does ChatGPT update what it knows about brands?
Training-data knowledge refreshes on a model cycle, historically every 6-12 months. Grounded retrieval via search tools refreshes near-realtime but only when a user query triggers it. Most brand-mention queries draw from training data so new content needs time to accumulate before it changes what ChatGPT says.
Do ChatGPT citations drive real traffic?
Yes. AI-referred traffic converts meaningfully higher than generic search traffic because the user arrives with the buying question already answered. The tradeoff is volume. ChatGPT cites one to three brands per answer so being #2 or #3 on a high-intent query is worth far less than being #1.
Is ChatGPT biased toward certain brands?
The model reflects its training data. Brands over-represented in English-language web content, tech press, Reddit, and Wikipedia will appear more often. This is neither intentional bias nor a bug. It is a structural property of supervised learning on the open web.
Start free
Run your free AI visibility audit.
60 seconds. No card.
We sweep 10 buyer-intent prompts across six AI platforms, score your brand on the same three-layer stack described above, and email a branded PDF within 24 hours with the specific layer you should fix first.
Get my free audit